面试复习-项目-HLFS
HLFS的存储体系结构
HLFS是开源云计算平台cloudxy的虚拟机镜像存储系统,为cloudxy提供安全、可靠、高效的分布式镜像存储服务。从实现方式上来讲,HLFS由三个逻辑层次组成:接口层、逻辑层、后台存储层。接口层主要以应用函数库的形式给虚拟机监管者(Virtual Machine Monitor)提供存储接口。逻辑层实现了核心功能,包括快照和回滚、文件系统组织等。HDFS(Hadoop分布式文件系统)是Hadoop应用程序的主要存储系统[6]。主要的特点是将数据的多个副本分布地存储于计算机集群的多个节点上,以提供存储的高可靠性。后台存储层借助HDFS实现存储集群管理。图1是HLFS的存储体系结构。
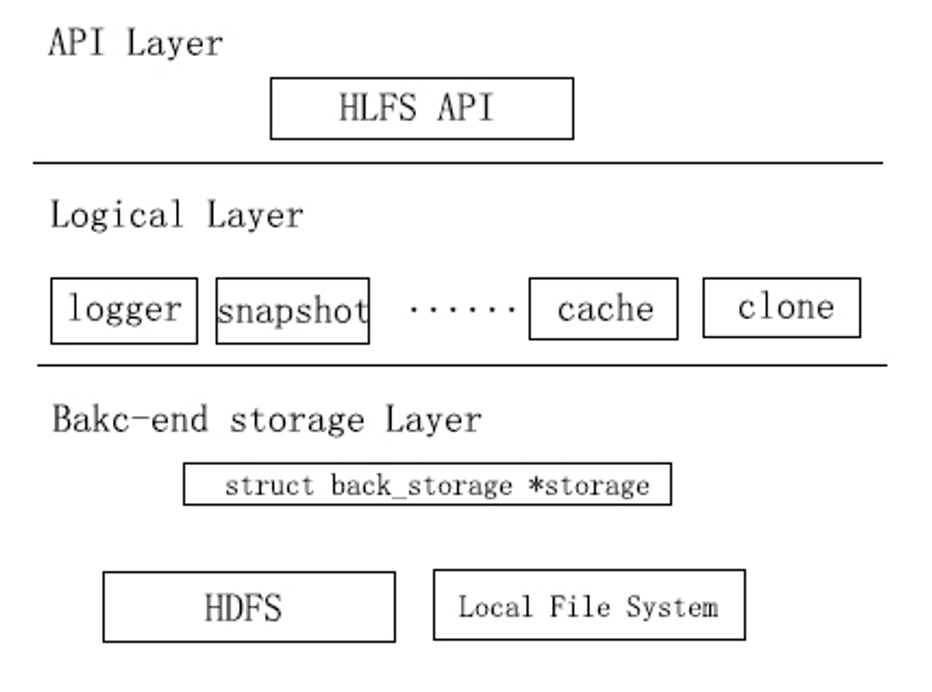
HLFS由三个组件构成:主节点(Name Node)、数据节点(Data Node)、客户端组成,如图2所示。主节点通过处理注册及心跳检测来维护数据节点的机架关系(cluster membership)、处理来自数据节点的报告及数据块的位置、处理文件数据块操作并管理文件数据块的冗余副本。数据节点在本地文件系统上存储HDFS的文件数据块。客户端通过则HLFS动态链接库来使用HLFS所提供的服务。
HLFS数据传输与控制信息的传输是分开的,这就有效的减少了主节点的负载。客户端在请求数据时,首先会从主节点获取数据块的位置及其他元数据,然后直接和数据节点进行数据传输,而不必有主节点的参与。
HLFS的数据组织方式
日志结构文件系统(Log-structured File System)是将文件中的数据和元数据封装成日志(Log),并将日志顺序地追加写入到磁盘的末尾。其实现的最初目的是加速磁盘写入操作及崩溃恢复。HLFS被设计成为一个简化的日志结构文件系统,具有高可用性、高性能、支持随机读写、快速故障恢复、支持数据快照与回滚、支持动态扩容等诸多特点。
HLFS并非完全遵循Posix语义,而是仅仅实现了单一文件的基本管理(open,write,read,close等)的块级(block-level)存储系统。从逻辑上讲,该存储系统是由很多个大小一致(最后一个段除外)的段(Segment)组成,每一个段又由数目不定的日志组成,如图所示。
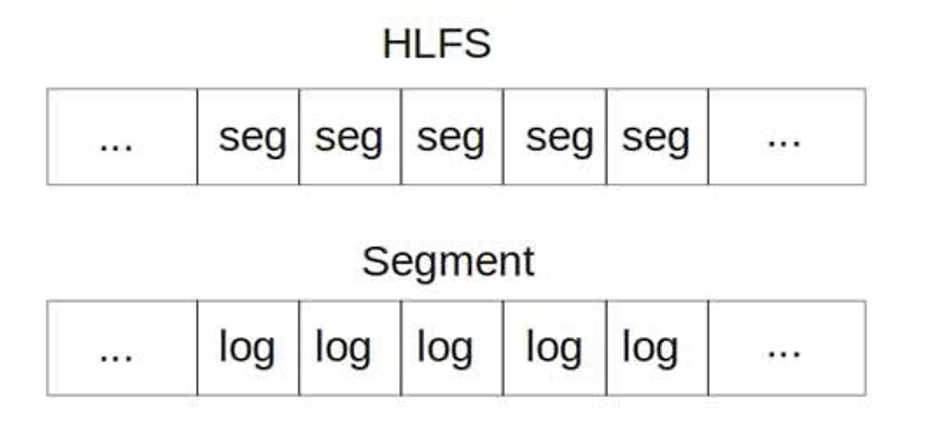
所有的段都是以分布式文件系统HDFS文件的形式存在,且有相应的编号作为数据的段地址。数据在段文件中的偏移量作为偏移地址。这样,所有的段叠加在一起就构成了一个具有线性地址空间的虚拟磁盘。日志(log)的结构如图4所示,每个log由日志头、数据块、间接块、索引节点(inode)、索引节点映射构成[9]。日志头记录了该日志的大小、生成时间等信息。数据块存放来自用户的数据,间接块和索引节点中存放有这些数据块的线性地址。除此之外,索引节点还保存了文件大小、时间信息以及间接块的线性地址。针对镜像存储的特点,HLFS目前被设计为只支持单一文件。
所有的log都指向了同一个索引节点。索引节点映射保存了该索引节点的索引结点号以及索引节点的地址。

缓存子系统设计思想及策略
由于客户端与后台HDFS集群的数据交互效率低下,频繁的I/O操作将会从很大程度上托慢系统的整体性能。为了解决这个问题,我们在客户端组件上设计并实现了一层缓存(Cache),让客户端的I/O先在缓存中进行,当系统空闲时或缓存充满时,再把缓存的内容刷回后台集群。这样,用户所感知的I/O时间减少,因而也提升了系统的响应速度。
在缓存子系统设计时,我们需要考虑以下两个问题:
1)缓存的置换策略。缓存失效或者资源被耗尽时,需要将缓存中一些缓存项(item)同步到后台集群。常用的置换策略有随机替换策略、最近最少使用策略(LRU)以及先进先出策略。随机替换策略是在缓存中随机选择一个或多个缓存项,将其同步到后台集群。最近最少使用策略是利用局部性原理将最近最少被访问的缓存项替换出去。先进先出策略是将最早进入缓存的缓存项替换出去。综合比较三种策略,先进先出策略和随机替换策略最容易实现,但效率相较于最近最少使用策略偏低,所以我们选取最近最少使用策略。
2)数据一致性。当引入缓存后,后台集群数据和缓存中的数据出现了不一致的情形。常用的缓存写数据同步策略有:写透(write through)式和写回(write back)式。写透式是在将数据写入缓存的同时,也将数据写入后台集群,而写回式则是将数据只写入缓存,待缓存耗尽或系统空闲时,再将数据刷回到后台集群。写透时保证了数据的一致性,但效率并没有写回式高,因而我们选取写回式数据同步策略。
缓存子系统的实现
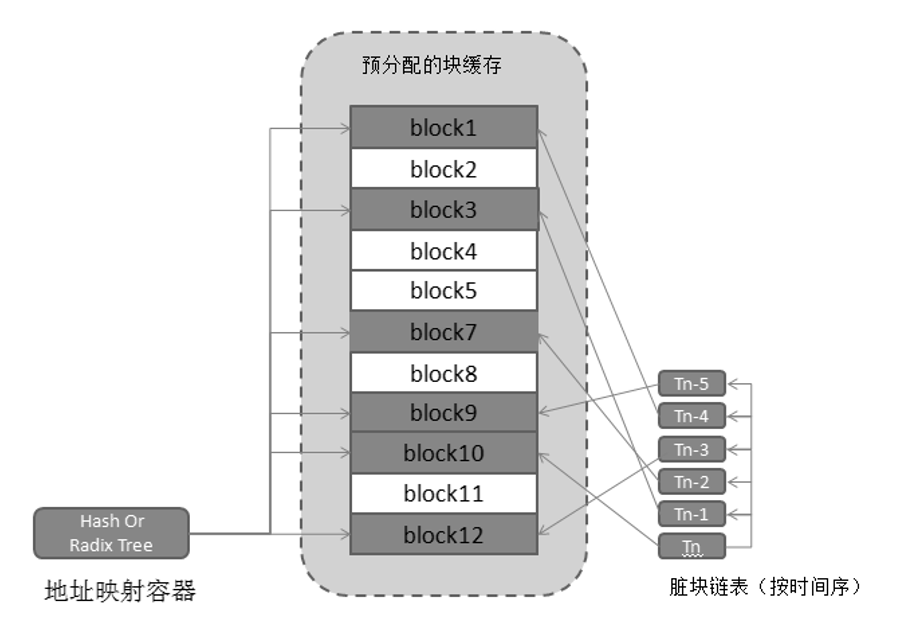
实现缓存(Cache)需要用到两个核心的数据结构:block_t和cache_ctrl。block_t描述了数据块的块号及其在内存中的地址,其定义如下:
1 | typedef struct { |
cache_ctrl是cache子系统的全局控制结构,记录了整个子系统所需要的重要信息,其定义如下:
1 | typedef struct cache_ctrl { |
缓存子系统初始化的时候会为cache_ctrl分配内存,并根据配置文件填充该结构体。之后,缓存子系统所有的控制数据都会从该数据结构中读取,所有的操作函数也会把cache_ctrl作为控制句柄。block_cache是利用glib库中的GTrashStack所做的块容器,系统在初始化的时候会分配固定数量(cache_size)的block_t结构,并存储于容器中。dirty_block是脏块的LRU链表,系统中所有的脏块地址都会按LRU算法存放于此队列中。哈希表block_map维护数据块号与数据块结构block_t的映射关系。write_callback_func是用户传入的回写数据到后台集群的回调函数,而write_callback_user_param则是传递给该函数的参数。
缓存子系统的实现策略如下:
- 数据结构cache_ctrl中记录了来自用户配置文件的脏快刷新阀值,在写缓存时,如果缓存中的脏块数量未达到该刷新阀值,则数据直接写入缓存。如果已经达到刷新阀值,则唤醒flush后台线程。flush后台线程会异步执行刷新操作。回写线程会检测cache中是否有容纳本次写入的空间,如果有则写入,没有则继续在等待队列上等待被唤醒。
- flush后台线程将cache中的脏块写回后,释放cache空间,并通知等待队列上的写入线程。
- flush后台线程执行有两个条件:一个是周期性时间到达,一个是被唤醒。
- flush后台线程每次写操作写入的脏块不能超过给定数量(每次写入对应一个log)。但会在循环中连续执行写入,直到脏块数低于阀值才停止,再次进入休眠状态。
- flush写下去的脏块直接归还到cache中。
- 读请求到来之后,首先会从缓存中查询是否有 缓存的块,如果没有再去从后台查询。
 微信
微信- 支付宝




