Linux虚拟化面试题汇总
CPU虚拟化是怎么实现的?
硬件辅助虚拟化的情况下,CPU提供了根模式和非根模式,VMM 运行在根模式下,拥有最高的特权级别,可以直接访问物理硬件资源。Guest OS 运行在非根模式(VMX)下,当它执行敏感指令时,处理器会自动切换到根模式,由 VMM 进行处理。
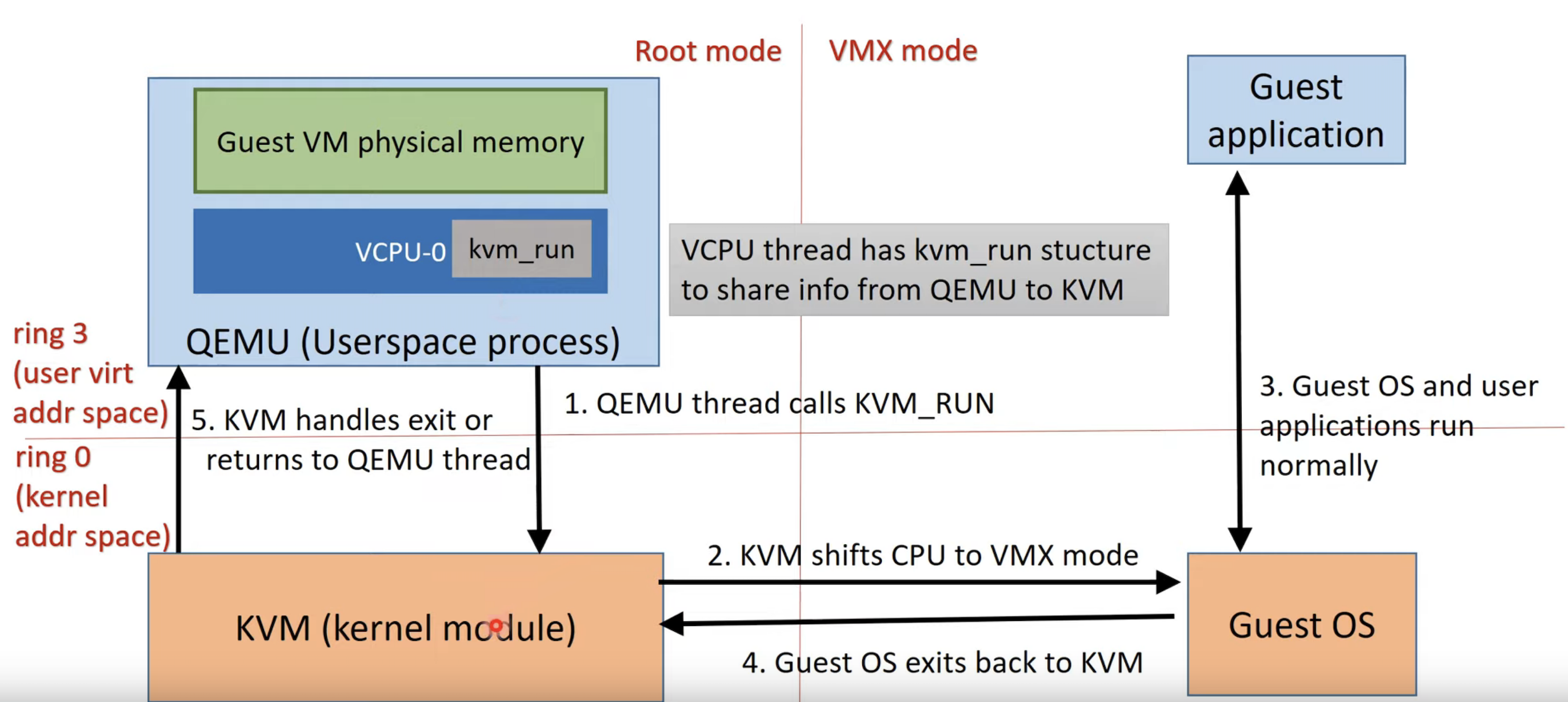
QEMU会为每个vcpu创建一个线程,这个线程会通过ioctl给KVM发送KVM_RUN指令让CPU进入VMX模式并切换成VM的上下文。
VMCB(VM控制块)可以被两种模式(root, vmx)访问,所以可以用来存储:
- HOST CPU上下文
- Guest CPU上下文
- Guest Entry/EXECUTION/EXIT 控制区,KVM可以配置哪些指令和异常能导致VM exit.
- Exit information: VM exit的原因
敏感指令包括:
- 访问或修改控制寄存器(如 CR0、CR3、CR4 等)的指令。这些寄存器控制着处理器的关键运行模式和特性。
- 执行输入 / 输出(I/O)指令。例如,直接对硬件设备进行读写操作的指令,因为这些指令可能会影响整个系统的稳定性和安全性。
- 启动和停止中断的指令。对中断的控制需要在特权级别下进行,以确保系统的正常运行和响应。
特权指令包括:
- 切换处理器运行模式的指令。例如,从用户模式切换到内核模式或监督模式的指令,这些指令通常只能在特定的特权级别下执行。
- 对内存管理单元(MMU)进行设置和控制的指令。包括设置页表、开启或关闭虚拟内存等操作,这些操作对于系统的内存管理至关重要,需要特权才能执行。
- 执行系统调用的指令
内存虚拟化是怎么实现的?
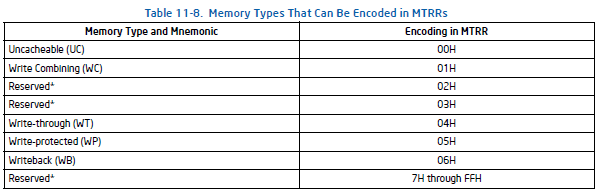
- MTRR(Memory Type Range Register). 物理内存可以被分成几个区域(range),每个区域对应于如下某一种内存类型:
- MMU(Memory Management Unit)内存管理单元实现了:
- 内存区域的访问保护
- 虚拟地址到物理地址的转换
- VMM可以通过EPT(Extended Page Table)实现:
- 防止虚拟机访问没有权限的页面
- 虚拟机物理地址到真实物理地址的转换
- TLB(Translation Lookaside Buffer)缓存了虚拟页号到物理页号的映射,如果TLB没有命中,从内存中查找页表的开销会非常大。
- VPID(Virtual Processor ID) TLB中通过VPID来标识缓存项所属的虚拟机,从而避免了每次VM_EXIT带来的TLB缓存失效的问题,极大的提高了效率
- 虚拟机在创建时QEMU会给每个虚拟机分配一块内存(mmap), 虚拟机的物理地址空间其实就是这块内存在QEMU中的虚拟地址空间,EPT扩展页维护了虚拟机物理地址到主机物理地址空间的映射,从而使虚拟机可以访问主机的内存。
- 虚拟机启动时,KVM 和 QEMU 协同工作,为虚拟机分配物理内存,并创建相应的页表结构。
- 当虚拟机中的应用程序访问内存时,KVM 会通过硬件辅助虚拟化技术将客户机虚拟地址转换为物理地址。
- QEMU 负责模拟硬件设备,并将对虚拟设备的内存访问转换为对物理内存的访问。
- 如果虚拟机需要更多内存,KVM 和 QEMU 会共同进行内存分配和管理,确保虚拟机有足够的内存可用。
- QEMU 还可以对内存进行优化和共享,以提高性能和减少内存使用量。
中断的处理
设备生成中断不考虑时钟同步,直接发送给中断控制器和CPU。异常的处理与中断类似,但考虑时钟同步,被称为同步中断
CPU收到中断后,内核会调用
do_IRQ()do_IRQ会获取中断号、保存被中断进程的上下文
do_IRQ根据中断号获取对应的中断处理程序
当中断处理程序结束后do_IRQ会将保存在内核栈中的进程上下文恢复
将程序计数器的值恢复为被中断进程的下一条指令
中断上下文不可以睡眠,中断处理程序并不具有自己的栈,它会共享被中断进程的内核栈。或者配置内核,让每个CPU都有一个页用作中断栈
中断处理程序分为上下两部分,上半部通常只执行有严格时限的工作,如中断应答、复位硬件、从网卡缓冲区把数据拷贝到内存等。下半部执行比较耗时的工作。
下半部执行的三种方式:
- 软中断:需要编译的时候就注册软中断,中断处理程序执行完硬件设备相关的操作后就会调用do_softirq()函数执行被raise_softirq(SOFTIRQ_TYPE)挂起的软中断。类型相同的软中断可以在所有处理器上同时执行。
- tasklet: tasklet其实是用软中断实现的(Hi_SOFTIRQ及TASKLET_IRQ)。它允许驱动程序动态的注册。类型相同的tasklet不能同时执行。
- 工作队列:通过在进程上下文中启动一个内核线程去执行,允许睡眠。系统有缺省的workqueue来处理数据,驱动程序也可以创建自己的workqueue来执行下半部的任务。对于一个workqueue,每个CPU上都有一个cpu_workqueue_struct来定义在该CPU上运行的内核线程
多线程访问一块内存的时候,怎么样优化其性能
- 可以将内存池化,可以避免频繁的分配与释放
- 使用无锁的结构:原子操作或者利用内存屏障实现无锁的队列
- 将数据分区,不同的线程处理不同区域的数据可以避免竞争
- 在读多写少的情况下,可以使用读写锁
- 使用细粒度锁
- 内存对齐
- 数据预取:根据线程的访问模式,提前将可能被访问的数据加载到缓存中,减少线程等待数据从内存加载到缓存的时间。
- 缓存行对齐:处理器在加载内存数据时通常是按照缓存行(一般为 64 字节)进行加载的,当多线程访问的数据位于不同的缓存行时,可以减少线程之间的缓存竞争。
介绍一下Virtio
Virtio 是一种 I/O 半虚拟化解决方案,主要用于提高虚拟机与宿主机之间的 I/O 性能.
基本架构
- 前端驱动(Guest Front - end Driver)
- 存在于虚拟机中:运行在虚拟机操作系统内部,它负责将虚拟机中的 I/O 请求传递到宿主机。例如,当虚拟机中的应用程序发起一个磁盘读写请求或者网络数据包发送 / 接收请求时,前端驱动会将这些请求按照 Virtio 规范进行封装。
- 适配 Virtio 规范:遵循 Virtio 的接口标准,将虚拟机的硬件设备抽象为 Virtio 设备,使得虚拟机操作系统可以像操作物理硬件设备一样操作这些虚拟设备。例如,在网络通信方面,前端驱动会将网络数据包按照 Virtio 网络设备的格式进行封装,准备发送给宿主机。
- 后端驱动(Host Back - end Driver)
- 位于宿主机上:在宿主机操作系统中运行,负责接收来自虚拟机前端驱动的 I/O 请求,并将这些请求转换为对物理硬件设备的实际操作。例如,当后端驱动接收到虚拟机发送的磁盘读写请求时,它会将这些请求转发给物理磁盘控制器进行处理。
- 硬件交互与资源管理:与物理硬件设备进行直接交互,管理和分配物理资源以满足虚拟机的 I/O 需求。例如,在内存管理方面,后端驱动需要确保虚拟机的内存与宿主机的物理内存之间的数据传输高效、安全地进行。
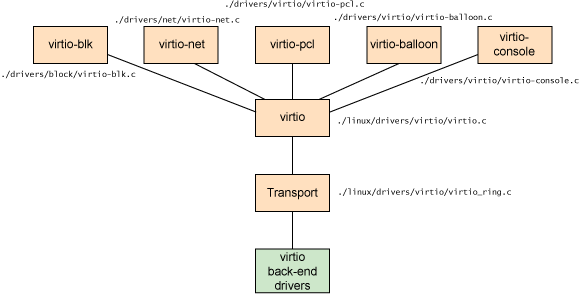
- virtio模块给前端驱动提供了操作virtqueue的接口。前端驱动可以根据需求创建一个或者多个virtqueue来与后端进行通信。
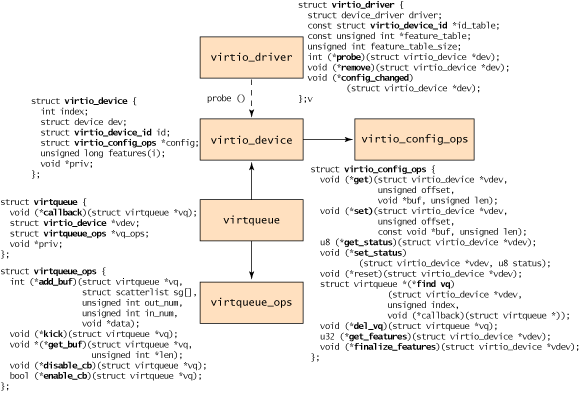
- virtio_driver结构体表示在虚拟机中的virtio前端驱动,在前端驱动模块初始化的时候,需要调用
register_virtio_driver来注册。它定义了上层的设备驱动以及所支持的设备ID,设备的feature table,以及一系列的回调函数。 - virtio_device结构体代表了虚拟机中的virtio设备。
- virtio_device引用的virtio_config_ops定义了配置virtio设备的一些操作
- virtqueue结构体中包含了其服务的virtio设备,以及virtqueue_ops
virtio使用流程:
- 前端驱动调用
register_virtio_driver来注册virtio驱动 - 当有virtio驱动支持设备列表中的设备加入后,会调用virtio_driver中注册的probe函数
- probe函数通常会调用
virtio_find_vqs来申请所需要的virtqueue - 当虚拟机需要向Hypervisor发送数据时,调用virtqueue_ops中的
add_buffer函数来添加数据,添加完成后调用kick通知Hypervisor - 虚拟机可以轮询
get_buffer函数来获取数据,也可以睡眠,等待被callback唤醒
介绍一下NUMA
NUMA(Non - Uniform Memory Access,非一致内存访问)是一种计算机内存设计架构,以下是它的相关介绍:
基本概念
内存节点:在 NUMA 架构中,系统的物理内存被划分为多个节点(Node)。每个节点都有自己的本地内存,并且可以被特定的一组处理器(通常是在物理位置上靠近该内存节点的处理器)更快地访问。例如,在一个具有两个 NUMA 节点的服务器中,节点 0 的内存对于与节点 0 紧密关联的处理器来说是本地内存,而对于节点 1 相关联的处理器来说则是远程内存。
处理器与内存的关联:每个处理器都有一个优先访问的本地内存节点,但也可以访问其他节点的内存(称为远程内存访问)。不过,访问远程内存的速度通常比访问本地内存慢,这是因为远程访问需要经过额外的内部互连线路(如 QPI 或 UPI 总线),会带来更高的延迟。
numactl --membind=0 <command>numactl --interleave=all <command>numactl --membind=0 --cpunodebind=0 -p 1234numactl --interleave=all <command>
Kubevirt是怎么实现虚拟机管理的
自定义资源定义(CRD)
- 定义虚拟机资源:Kubevirt 在 Kubernetes 基础上定义了一系列与虚拟机相关的自定义资源,如 VirtualMachine(VM)、VirtualMachineInstance(VMI)等。这些 CRD 允许用户像管理 Kubernetes 原生资源(如 Pod、Deployment 等)一样管理虚拟机。例如,用户可以通过创建一个 VMI 资源的 YAML 文件,描述虚拟机的规格(如 CPU、内存、磁盘等)、网络配置等信息,然后将其提交给 Kubernetes API 服务器进行创建。
- 扩展 Kubernetes API:通过 CRD,Kubevirt 扩展了 Kubernetes 的 API,使 Kubernetes 能够理解和处理虚拟机相关的操作。这意味着可以使用 Kubernetes 的命令行工具(如 kubectl)来管理虚拟机的整个生命周期,包括创建、启动、停止、删除等操作。例如,kubectl create -f <vmi - yaml - file>可以根据指定的 VMI YAML 文件创建一个虚拟机实例。
- 管理虚拟机生命周期:Kubevirt 利用 Kubernetes 的控制器模式来管理虚拟机的生命周期。它包含了多个控制器,每个控制器负责特定的任务。例如,VirtualMachineController 负责处理 VirtualMachine 资源的创建、更新和删除操作,并将其转换为对 VMI 资源的操作。当用户创建一个 VirtualMachine 资源时,VirtualMachineController 会根据其配置创建相应的 VMI 资源,并确保它们的状态保持一致。
- 协调资源状态:控制器会不断监控虚拟机相关资源的状态,并根据需要进行调整和协调。例如,如果一个 VMI 资源的状态变为异常(如虚拟机崩溃或网络故障),相关的控制器会尝试采取恢复措施,如重启虚拟机或重新配置网络。这与 Kubernetes 管理 Pod 等资源的方式类似,通过控制器的协调机制来确保系统的稳定性和可靠性。
网络管理
- 集成 CNI 插件:Kubevirt 集成了容器网络接口(CNI)插件来实现虚拟机的网络连接。CNI 插件负责为虚拟机分配网络地址、配置网络路由以及提供网络服务(如 DHCP、DNS 等)。例如,当一个虚拟机启动时,Kubevirt 会调用相应的 CNI 插件(如 Multus CNI)为其创建网络接口,并根据网络配置将虚拟机连接到指定的网络中。
- 支持多种网络模式:除了基本的网络连接,Kubevirt 还支持多种复杂的网络模式。例如,在多租户环境中,可以通过网络策略(Network Policy)来控制虚拟机之间的网络访问权限,实现网络隔离和安全控制。另外,对于需要高性能网络的场景,Kubevirt 可以支持 SR - IOV 等硬件加速技术,提高虚拟机的网络吞吐量和降低网络延迟。
存储管理
- 使用存储卷:Kubevirt 利用 Kubernetes 的存储卷(Volume)概念来管理虚拟机的存储。用户可以在 VMI 资源中定义存储卷的类型(如 PersistentVolumeClaim - PVC、HostPath 等)、大小和挂载点。例如,通过创建一个 PVC 并将其挂载到虚拟机内部的特定目录,虚拟机可以使用持久化存储来保存数据。这使得虚拟机的数据可以独立于虚拟机的生命周期进行管理,即使虚拟机被删除,数据仍然可以保留在存储卷中。
- 存储插件支持:Kubevirt 支持多种存储插件,如 Ceph、GlusterFS 等。这些存储插件可以提供高性能、高可靠的存储服务,满足不同场景下虚拟机的存储需求。例如,在大规模集群环境中,可以使用 Ceph 作为存储后端,为虚拟机提供分布式、可扩展的存储资源。同时,存储插件还支持动态存储供应(Dynamic Provisioning),即根据虚拟机的需求自动创建和分配存储资源。
Linux是如何管理内存的
- page结构体用来表示一个物理页面,其包含引用计数、虚拟地址等信息
- alloc_pages(gfp_mask, order)可以分配2 ** order个连续的物理页,返回第一个页的page结构体
- __get_free_page(gfp_mask, order)返回所分配第一个页的虚拟地址
- 内核用slab为内核中用到的数据结构分配空间,slab通常由物理连续的内存页组成,一个slab可以存储多个同类型内核对象
什么是SR-IOV
SR - IOV(Single Root I/O Virtualization)即单根 I/O 虚拟化,以下是关于它的详细介绍:
基本概念
物理功能(PF)和虚拟功能(VF)
- 物理功能(PF):在 SR - IOV 架构中,物理功能(PF)是指物理设备(如网卡、显卡等)本身所具备的完全功能的接口。它可以像传统的物理设备一样被操作系统识别和配置。例如,在一个支持 SR - IOV 的网卡中,PF 可以进行复杂的网络配置、驱动程序更新等操作,并且拥有对物理设备的完全控制权。
- 虚拟功能(VF):虚拟功能(VF)是从物理功能(PF)中派生出来的轻量级的虚拟接口。VF 与 PF 共享物理设备的硬件资源,但它的功能相对简化,只包含了与数据传输相关的必要功能。例如,一个支持 SR - IOV 的网卡可以创建多个 VF,每个 VF 都可以被分配给一个虚拟机或者容器,使它们能够直接访问物理网络,而无需经过复杂的软件模拟。
工作原理
- 资源分配与共享
- 硬件资源划分:SR - IOV 技术在硬件层面将物理设备的资源(如内存、带宽、中断等)划分为多个部分,分别分配给 PF 和 VF。例如,在一个网卡中,硬件会将一定的缓存空间、数据传输带宽等资源分配给每个 VF,确保 VF 在进行数据传输时能够获得稳定的性能。
- 共享物理设备:VF 与 PF 共享物理设备的物理端口、链路层控制器等硬件组件。这样,多个 VF 可以同时利用物理设备的高速数据传输通道,提高了硬件资源的利用率。例如,在一个 10Gb/s 的网卡上,通过 SR - IOV 创建多个 VF 后,这些 VF 可以共同使用网卡的 10Gb/s 带宽进行数据传输。
- 设备发现与配置
- BIOS 和硬件初始化:在系统启动过程中,BIOS 和硬件会进行初始化操作,检测和配置 SR - IOV 相关的硬件组件。例如,在服务器主板的 BIOS 设置中,可能会有关于 SR - IOV 的启用选项,当启用该选项后,系统启动时会自动检测支持 SR - IOV 的设备,并进行相应的初始化工作。
- 操作系统和驱动程序支持:操作系统和设备驱动程序需要对 SR - IOV 进行支持,才能正确识别和配置 PF 和 VF。例如,在 Linux 操作系统中,内核需要加载支持 SR - IOV 的网络驱动程序,该驱动程序会与硬件进行交互,发现并配置 PF 和 VF。当一个 VF 被分配给一个虚拟机时,虚拟机中的操作系统也需要相应的驱动程序来识别和使用 VF。
技术优势
- 提高网络性能
- 降低虚拟化开销:在传统的虚拟化环境中,虚拟机通过软件模拟的方式共享物理网络设备,这会带来一定的性能开销。而 SR - IOV 通过硬件直接分配 VF 给虚拟机,减少了软件模拟的中间环节,从而降低了网络延迟和提高了网络吞吐量。例如,在高性能计算、大数据处理等对网络性能要求较高的场景中,使用 SR - IOV 可以显著提高数据传输效率。
- 实现接近物理设备的性能:VF 可以直接访问物理设备的硬件资源,使得虚拟机或者容器在网络性能上能够接近使用物理设备的性能。例如,在一个测试环境中,对比使用传统虚拟网卡和使用 SR - IOV 的 VF 的虚拟机的网络性能,可以发现使用 VF 的虚拟机在网络延迟和吞吐量方面都有明显的提升。
- 增强资源利用率和灵活性
- 灵活分配资源:SR - IOV 允许根据不同的需求灵活地创建和分配 VF。例如,在一个数据中心中,对于不同的业务应用(如 Web 服务、数据库服务等),可以根据其网络负载特点分配不同数量的 VF,实现资源的优化配置。
- 提高硬件资源复用率:通过创建多个 VF,可以在同一物理设备上同时为多个虚拟机或者容器提供服务,提高了硬件资源的复用率。例如,在一个拥有多个虚拟机的云计算环境中,使用 SR - IOV 技术的网卡可以支持更多的虚拟机同时进行网络通信,而无需额外增加物理网卡的数量。
Linux的进程是怎么创建的
- 进程是操作系统管理与分配资源的主体,它在Linux中用task_struct来表示,进程描述符包含了打开的文件、挂起的信号、进程的地址空间、进程的状态等信息。
- 每个进程都会有一个1页或者2页的内核栈,栈底保存了
thread_info结构体,内核可以通过它找到在slab分配器中动态分配的task_struct - 进程有如下的状态
- TASK_RUNNING:正在执行或者在运行队列等待执行
- TASK_INTERRUPTIBLE:可中断睡眠
- TASK_UNINTERRUPTIBLE: 不可中断睡眠
- __TASK_TRACED
- __TASK_STOPPED
创建过程:
- 调用
dup_task_struct为子进程创建一个内核栈、thread_info和task_struct,值与当前进程相同 - 检查资源是否足够
- 子进程设置自己的进程描述符
- 子进程的状态被设置为TASK_UNINTERRUPTIBLE
- 设置PF_SUPERPRIV、PF_FORKNOEXEC等flag
- 分配有效的PID
- 根据标志选择是否共享或者拷贝打开的文件、文件系统信息、信号处理函数、进程地址空间、命名空间等信息
线程的创建通常是通过clone系统调用来做的,和进程的创建过程类似。只不过是标志位设置成了CLONE_VM|CLONE_FS|CLONE_FILES|CLONE_SIGHAND以共享进程的地址空间、文件系统信息、文件描述符、信号处理程序。
内核线程与普通进程的区别在于没有自己的地址空间,即task_struct中的mm被设置为NULL。
销毁过程:
- 设置标志位PF_EXITING
- 删除内核定时器中的任务
- 如果mm_struct没有被共享,则释放
- 如果进程在等待IPC信号,则从队列中删除
- 减少文件系统信息以及文件描述符的引用计数,如果清零就释放
- 设置task_struct中的退出状态码
- 给子进程找养父进程,线程组中的其他进程或者init进程
- 状态设置为
TASK_ZOMBIE,仅保留了内核栈、thread_info、task_struct给父进程提供信息 - 如果父进程检索到了信息,就将上述剩下的资源释放
Linux的进程是怎么调度的
- Linux的调度器是通过模块和调度器类实现的,在系统需要调度的时候,会从调度器中选择优先级最高的调度器进行调度
| 调度类 | 调度策略 | 调度对象 |
|---|---|---|
| stop_sched_class(停机调度类) | 无 | 停机的进程 |
| dl_sched_class(限期调度类) | SCHED_DEADLINE | dl进程 |
| rt_sched_class(实时调度类) | SCHED_RR 或者 SCHED_FIFO | 实时进程 |
| fair_sched_class(公平调度类) | SCHED_NORMAL 或者 SCHED_BATCH | 普通进程 |
| idle_sched_class(空闲调度类) | SCHED_IDLE | idle进程 |
- 优先级关系:
stop_sched_class > dl_sched_class > rt_sched_class > fair_sched_class > idle_shced_class
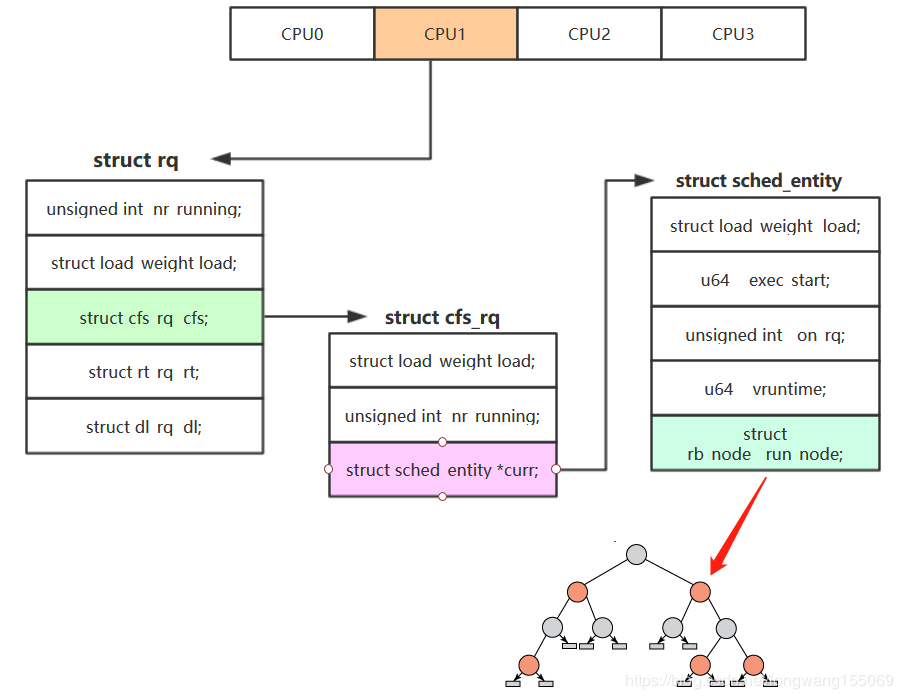
- CFS(完全公平调度器)是Linux内核2.6.23版本开始采用的进程调度器,它的基本原理是这样的:设定一个调度周期
sched_latency_ns,目标是让每个进程在这个周期内至少有机会运行一次,换一种说法就是每个进程等待CPU的时间最长不超过这个调度周期;然后根据进程的数量,大家平分这个调度周期内的CPU使用权,由于进程的优先级即nice值不同,分割调度周期的时候要加权;每个进程的累计运行时间保存在自己的vruntime字段里,哪个进程的vruntime最小就获得本轮运行的权利。 进程的运行时间 = (调度周期时间 * 进程的weight) / CFS运行队列的总weightSCHED_FIFO和SCHED_RR用来调度实时进程,SCHED_FIFO会一直占用CPU直到自己退出或者被优先级更高的实时进程抢占,SCHED_RR是同样优先级的实时进程按照时间片轮转调度- Linux中的普通进程用的是CFS完全公平调度算法来进行调度,他通过计算虚拟运行时间
vruntime,选择vruntime最小的进程进行调度 task_struct中的sched_entity记录了虚拟运行时间vruntime,内核用自平衡二叉搜索树红黑树来组织可运行进程队列vruntime += 实际运行时间 * (NICE_0_LOAD/NICE_LOAD)NICE_0_LOAD为nice值为0时的权重,NICE_LOAD为当前进程nice值的权重schedule()会调用context_switch()来:switch_mm():切换新进程的虚拟地址空间switch_to():切换新进程的处理器状态
- 内核会在系统调用、中断处理结束后返回用户空间时,检查
need_resched标志,如果被设置则重新调度,抢占用户程序的执行 - 进程
threed_info中的preempt_count记录了持有锁的数量,如果为0表明可以被抢占
如果虚拟机出现了故障,可以用哪些Linux命令去解决
top/htop
- 作用:实时显示系统中各个进程的资源占用情况,包括 CPU、内存、交换空间等。top是 Linux 系统自带的基本工具,而htop是一个功能更加强大、界面更加友好的进程监控工具。例如,通过top命令可以看到哪些进程占用了大量的 CPU 资源或者内存资源
free
- 作用:显示系统内存(包括物理内存和交换空间)的使用情况。例如,free -m以 MB 为单位显示内存的总量、已使用量、空闲量、共享内存量以及缓冲和缓存占用量等信息。
- 故障场景示例:如果虚拟机出现内存不足相关的错误(如应用程序因内存耗尽而崩溃),可以使用free命令查看内存的使用情况,确定是否需要增加虚拟机的内存分配或者优化内存使用。
1
2
3
4
5
6total:表示系统总的可用物理内存大小,计算公式为total = used + free + buff/cache。
used:已被使用的物理内存大小。
free:未被使用的物理内存大小,这部分内存是完全没有被占用的。
shared:多个进程共享的内存大小,通常在某些特殊的进程间通信或者共享内存场景下会有数据。
buff/cache:这是内核缓冲区(buffer)和页面缓存(cache)的大小总和。缓冲区用于存储块设备(如磁盘)的读写缓冲数据;页面缓存用于缓存文件系统中文件的页面数据,以提高文件读写的效率。
available:这是一个估计值,表示新的应用程序还可以使用的物理内存大小。它考虑了系统中未被使用的内存、可回收的缓存等因素,是一个对应用程序可分配内存更准确的评估。
iostat
- 直接在命令行输入iostat,会显示系统整体的 CPU 使用情况以及各个磁盘设备的 I/O 统计信息
- 磁盘性能评估:通过iostat可以查看磁盘的读写速度、I/O 操作次数等信息,从而评估磁盘的性能。例如,如果kB_read/s和kB_wrtn/s的值非常低,而%iowait的值较高,可能表示磁盘性能不足或者存在 I/O 瓶颈。
- I/O 瓶颈排查:当系统整体性能出现问题,怀疑是磁盘 I/O 导致时,iostat -x可以提供详细的磁盘 I/O 信息。比如,如果r_await或w_await的值很大,说明磁盘读写操作的等待时间过长,可能存在磁盘故障、磁盘负载过高或者其他影响磁盘性能的因素。
- 磁盘负载监控:在一个多用户或者多任务的环境中,使用iostat可以监控各个磁盘设备的负载情况。例如,在一个数据库服务器中,通过定期查看磁盘的tps和%util等指标,可以了解磁盘的繁忙程度,以便及时调整数据库的存储策略或者优化服务器的配置。
netstat
- 网络连接监控:通过netstat可以查看当前系统与外部主机建立的网络连接情况。例如,在排查网络故障时,查看是否存在异常的网络连接(如未知的远程连接或者过多的连接)。如果发现某个应用程序建立了大量异常的连接,可能存在安全风险或者程序故障。
- 服务监听检查:使用netstat -l可以检查系统中哪些网络服务正在监听特定的端口。例如,在配置 Web 服务器后,可以通过该命令确认 Web 服务是否正确地在 80 端口(或者其他指定端口)进行监听。
- 网络协议统计分析:netstat -s提供的网络协议统计信息对于分析网络性能和排查网络问题非常有帮助。比如,如果tcp协议的重传数据包数量过多,可能表示网络存在不稳定或者拥塞的情况,需要进一步检查网络设备或者网络配置。
- 进程与网络连接关联:结合-p参数可以确定哪些进程在使用网络资源。例如,当系统出现网络带宽异常占用的情况时,通过netstat -p可以找到相关的进程,进而分析该进程是否正常或者是否需要进行优化。
在Openstack环境中,虚拟机初始化的时候是怎么配置ssh key的
自动化脚本添加:可以编写脚本在镜像制作过程中自动添加 SSH Key 公钥。例如,使用脚本语言(如 Python)结合相关的镜像操作工具(如guestfish)来操作镜像。脚本可以在镜像中创建/root/.ssh目录(如果不存在),并将公钥写入到authorized_keys文件中。这样制作出来的镜像在每次创建虚拟机实例时,都已经包含了预先配置好的 SSH Key 公钥。
使用元数据服务注入公钥
- 原理:OpenStack 提供了元数据服务,虚拟机在启动过程中可以通过网络获取元数据信息。在制作镜像时,在镜像中配置一个脚本(如在 Linux 系统中可以是一个cloud - init脚本),该脚本在虚拟机启动时会从元数据服务获取 SSH Key 公钥信息,并将其添加到相应的位置。
- 具体操作:在镜像制作过程中,将cloud - init相关的软件包安装到镜像中,并在镜像的启动配置文件(如/etc/rc.local或者/etc/cloud/cloud.cfg)中添加执行获取和配置公钥的脚本命令。例如,脚本可以从元数据服务的特定 URL(如http://169.254.169.254/openstack/latest/meta_data.json)获取包含 SSH Key 公钥的元数据信息,然后将公钥写入到/root/.ssh/authorized_keys文件中。
TCP的连接是怎么建立的
TCP段中的标志位有:
- SYN: 同步标志,用于建立连接
- ACK: 确认标志,表示确认收到请求
- RST: 复位标志,用于复位相应的 TCP 连接
- PSH: 推标志,用于请求立即将数据交付给接收方的应用程序,而不是在缓冲区中等待
- FIN: 结束标志,用于请求关闭连接
- URG: 紧急标志,用于指示数据包中的数据应被优先处理。
TCP建立连接的步骤如下:
- 客户端发送一个标志位SYN为1、序列号为随机数x的数据段给服务器端,并进入SYNC-SENT状态
- 服务器端回复一个ACK标志位为1、SYN标志位为1、顺序号为
x+1、应答号为随机数y的数据段表示接受连接,并进入SYNC-RCVD状态 - 客户端再发送给服务器端一个ACK标志位为1、顺序号为
x+1、应答号为y+1的数据段,并进入ESTABLISHED状态 - 服务器端收到上述数据段后进入ESTABLISHED状态
TCP关闭连接的步骤如下:
- 客户端发送一个标志位FIN为1的数据段,并进入
FIN_WAIT_1状态 - 服务器端收到后会发送个客户端一个ACK为1的数据段并进入
CLOSE_WAIT状态 - 服务器端发送一个FIN 和 ACK 标志位都被设置为 1的数据段,进入
LAST_ACK状态 - 客户端发送一个ACK为1的报文给服务器端,进入
TIME_WAIT状态,服务器收到后进入CLOSED状态 - 客户端等待
2*MSL的时间后进入CLOSED状态
TCP 关闭连接时客户端在TIME_WAIT状态下会等待 2 倍的最大报文段生存时间(2MSL),主要原因如下:
确保 ACK 被接收
当客户端发送最后一个 ACK 确认报文段以响应服务器的 FIN 报文段后,这个 ACK 报文段可能在传输过程中丢失。如果丢失,服务器将重新发送 FIN 报文段。
客户端在 TIME - WAIT 状态等待 2MSL 时间,能够确保它有足够的时间收到服务器重传的 FIN 报文段,并再次发送 ACK 确认报文段。使旧连接的报文段在网络中消失
TCP 连接使用 IP 地址和端口号来标识。在网络环境中,可能存在报文段由于网络延迟等原因而延迟到达的情况。
当一个新的连接建立时,如果之前旧连接的报文段仍在网络中传播,可能会干扰新连接。等待 2MSL 时间可以保证本次连接中产生的所有报文段都从网络中消失,从而避免旧的连接报文段对下一个 TCP 连接造成干扰。
如何设计一个软件
Linux系统的设计理念”Do one thing, and do it well”,每个Linux命令都只做很小的功能,但通过Shell的组合可以实现更为复杂的功能。这点和函数式编程的风格也比较类似。所以在做架构设计的时候尽量让模块功能明确,可以提高可重用性以及快速的定位和分析问题。
在交互设计的时候尽量遵循现有的一些规范,如RESTful API。接口的设计需要明确,尽量不要有重复的、叠加的功能。
在数据存储方面,尽量避免多个组件共同直接操作数据库,需要设计一个单独的组件来负责数据的处理。
为提升性能,可以考虑设计与实现缓存系统。
需要设计和实现日志系统,尽量让日志信息详细、准确以便快速定位和分析问题。
设计一个高性能的存储系统
可以实现一个缓存
设备虚拟化可以从半虚拟化下移到硬件辅助虚拟化以提升性能
使用异步I/O或者I/O多路复用可以批量处理数据以提升性能
可以通过写时复用等技术延后处理极有可能不用处理的数据
后台线程如清理程序的设计可以给上层提供较全面的接口,以便上层组件可以根据实际的业务需求去更改配置进行性能优化
重构的时机,重构的代码如何保证,如何和设计模式结合
代码的可扩展性及可重用性太差,实现新功能的代价远大于重构的代价的时候应该进行重构。拿我所做的IaaS镜像自动化的项目举例来说,原先的设计是
每个操作系统类型、版本都对应了一套构建脚本以及Devops pipeline,然而,随着支持的操作系统越来越多,版本越来越多,支持新的操作系统或者版本
的代价将会变的很大。这个时候就需要进行重构,让多个操作系统、多个版本的构建脚本统一起来。重构软件时,可以利用不同技术的脚手架工具,让项目的内容尽可能的完整。如python或者js的脚手架工具会帮我们生成完整的目录结构。如文档、代码、单元测试、
集成测试、E2E测试、脚本工具等。重构的代码应该有完善的Devops管理机制。如CI的时候,需要不同的开发人员来评审代码,PR中的新代码单元测试的代码覆盖率达到80%等。部署的时候需要
对不同的环境的权限进行严格的管理,如开发环境、staging、产品环境。设计模块的功能尽量明确和单一,可以保证代码的可重用性,也可以能够尽快的分析出问题。另外可以实现抽象层,抽象层只需要定义一些接口,而具体的
功能可以用过下层的驱动或者适配层来完成。
已知有快照等特性,设计存储系统容灾架构、及关键组件
数据采集器:负责从混合云或者其他的数据中心接收或者采集所需要备份的数据和元数据
IAM: 负责身份认证、秘钥管理和权限管理等内容
元数据管理器:负责将其他组件生成的元数据保存到系统数据库中
数据管理器:负责数据的校验、去重等功能,并调用元数据管理器将元数据写入数据库
消息队列:负责各个组件的通信
后端存储器:将数据落地到跨AZ或者地区的分布式的存储系统
API服务器:提供对外的RESTful API访问
SDK, CMD tool, library, UI
API的分类可以有:数据源的管理,定时策略,备份区域管理,数据备份策略,数据的读写等功能,秘钥管理
当前项目代码行数大概多少
… …
 微信
微信- 支付宝