GPU虚拟化技术系列一:设备虚拟化基础
虚拟化基础
虚拟化技术是云计算与 AIInfra 的基石,其本质是通过虚拟机监控器(VMM/Hypervisor) 这一软件抽象层,将物理硬件资源(CPU、内存、设备)抽象为多个隔离的虚拟环境,实现资源的高效复用与安全隔离。
要构建稳定、高效的虚拟化系统,需突破三大核心技术瓶颈:CPU 特权级隔离、内存地址转换嵌套、设备 I/O 性能损耗。本章将从这三大维度切入,系统解析虚拟化基础原理,为后续 GPU 虚拟化技术的深入分析铺垫底层逻辑。
CPU 虚拟化:解决特权指令的 “权限冲突”
CPU 是虚拟化的核心内容,x86 架构的设计历史导致其天然存在 “特权指令未完全隔离” 的问题,这也是 CPU 虚拟化需要突破的首个关键卡点。
CPU虚拟化需要解决的问题:特权指令设计无法满足虚拟化权限隔离需求
虚拟化要求实现 “双重权限隔离”:
- Hypervisor 必须运行在最高特权级(Ring 0),完全控制物理硬件
- 虚拟机中的客户操作系统(Guest OS)需运行在非特权级(Ring 1-3),其操作需经过 Hypervisor 的监管
然而,x86 架构在设计时未考虑虚拟化场景,早期的CPU存在 17 条左右的 “敏感指令”(如LGDT加载全局描述符表、POPF恢复标志寄存器)—— 这些指令直接操作系统核心状态,但在非特权模式(Ring 1-3)下执行时不会触发 CPU 异常,导致 Hypervisor 无法拦截并控制,这会导致Guest OS可以直接修改关键硬件状态,绕过Hypervisor的监管,破坏整个系统的稳定性和安全。
解决方案演进
| 技术方案 | 原理 | 优缺点 |
|---|---|---|
| 全虚拟化 | 通过二进制翻译(BT)动态替换敏感指令 | 兼容性好(无需修改Guest OS),但性能损失大 |
| 半虚拟化 | 修改Guest OS内核,通过Hypercall主动调用Hypervisor (Ring1->Ring0) | 性能高(如Xen),但需定制OS |
| 硬件辅助虚拟化 | CPU新增虚拟化指令集(Intel VT-x/AMD-V),引入Root/Non-Root模式 | 原生支持特权隔离(VMXON指令进入虚拟化模式),性能接近物理机(现代主流方案) |
硬件辅助虚拟化实现的关键点
VT-x 的核心数据结构:
- VMCS(虚拟机控制结构):为每个虚拟 CPU(vCPU)维护独立的状态空间,包含寄存器、控制标志等,实现 vCPU 切换时的快速上下文保存 / 恢复;
- EPT(扩展页表):硬件直接支持 “Guest 虚拟地址→Guest 物理地址→主机物理地址” 的三级转换,避免 Hypervisor 干预。
虚拟机性能优化措施:
- vCPU 绑定物理核(Pinning):将 vCPU 固定到某一物理核,避免跨核迁移导致的 TLB(地址转换缓存)刷新,减少性能波动;在QEMU/KVM实现是则是将vCPU(线程)绑定到物理CPU上去运行(CPU亲和性)
- NUMA 感知调度:根据物理机 NUMA 节点拓扑分配 vCPU 与内存,避免跨节点访问的延迟(尤其对多 socket 服务器关键)。
内存虚拟化:解决地址转换的嵌套难题
内存是操作系统需要管理的另一重要硬件资源,虚拟化场景下需处理 “Guest 虚拟地址→Host 物理地址” 的双重转换,如何降低转换开销、保证缓存一致性,是内存虚拟化的核心挑战。
问题复杂性
- 地址转换链的拉长:物理机中仅需 “虚拟地址→物理地址” 一次转换,而虚拟化场景下需经过两级转换:
1 | Guest虚拟地址(GVA) → Guest物理地址(GPA) → 宿主机物理地址(HPA) |
- TLB 一致性风险:Guest OS 修改自身页表时,若未同步到 Host 的转换表,会导致 TLB 缓存失效,引发 “地址翻译错误”,需 Hypervisor 维护多级页表的一致性。
技术方案对比
| 实现方式 | 工作原理 | 性能影响 |
|---|---|---|
| 影子页表 | Hypervisor 为每个 Guest OS 维护一份 “GVA→HPA” 的直接映射表(影子表),Guest 页表修改时同步更新影子表 | 开销大:每次页表更新需触发 VM-Exit |
| 硬件辅助(EPT/NPT) | CPU直接处理GVA→GPA→HPA转换(Intel EPT/AMD NPT) | 减少VM-exit次数,性能大幅提升 |
| 大页(Huge Page)支持 | 启用 2MB-1GB 大页,减少页表项数量,降低 TLB Miss(地址缓存未命中)概率,需 Guest 与 Host 协同配置 | 缓存效率提升:TLB 命中率从 60% 提升至 90%+,尤其对数据库、AI 训练等大内存负载收益显著 |
内存虚拟化性能优化技术
- Balloon 驱动(气球驱动):Guest OS 中加载气球驱动,当 Host 内存紧张时,驱动 “充气” 回收 Guest 闲置内存,分配给其他虚拟机(如 VMware Tools、QEMU Guest Agent 内置);
- 内存去重(KSM):Host 通过哈希算法比对多个 VM 的内存页,合并内容相同的页(如多个 Linux VM 的内核代码段),节省 30%-50% 内存开销;
- 内存热插拔:支持运行时动态调整 VM 的内存配额(需 Guest OS 内核支持),适配业务负载的弹性需求(如 AI 训练任务扩容时临时增加内存)。
设备虚拟化:I/O性能的瓶颈突破
设备 I/O(如网卡、磁盘、GPU)是虚拟化性能的关键短板 —— 传统软件模拟的 I/O 延迟高达微秒级,无法满足高吞吐、低延迟场景(如 AI 推理、高频交易)。设备虚拟化的核心目标,是在 “兼容性” 与 “性能” 之间找到最优解。
虚拟化层次
| 实现层级 | 延迟水平 | 核心原理 | 典型场景 |
|---|---|---|---|
| 全模拟设备 | 微秒级(μs) | Hypervisor 完全用软件模拟物理设备的寄存器、中断逻辑(如 QEMU 模拟 e1000 网卡) | 兼容旧设备(如QEMU模拟的e1000网卡) |
| 半虚拟化驱动 | 亚微秒级(100ns) | Guest OS 安装专用半虚拟化驱动(如 Virtio),通过共享内存与 Host 直接通信,减少 VM-Exit | 高性能场景(如Virtio-net/virtio-blk) |
| 硬件直通(PCIe Passthrough) | 纳秒级(ns) | 将物理 PCIe 设备直接分配给 VM,VM 通过 IOMMU 直接访问设备,完全绕过 Hypervisor | GPU虚拟化、NFV(如SR-IOV网卡) |
关键技术
现代设备虚拟化的高性能,依赖三大核心技术体系:
- Virtio 架构:半虚拟化的事实标准,通过 “前后端分离 + 共享内存” 降低延迟:
- 前端驱动:运行在 Guest OS 中,标准化接口(如virtio-scsi磁盘驱动、virtio-net网卡驱动),无需感知底层硬件;
- 后端设备:运行在 Host(如 QEMU)中,实现设备的实际功能(如将virtio-blk请求映射到 Host 磁盘文件);
- vring 队列:基于环形缓冲区的异步 I/O 机制,前端与后端通过 vring 交换请求 / 响应,避免频繁的 VM-Exit。
- SR-IOV(单根 I/O 虚拟化):硬件级共享技术,将物理设备虚拟为多个 “虚拟功能(VF)”:
- 物理设备(如 GPU、网卡)包含一个 “物理功能(PF)” 和多个 “虚拟功能(VF)”,PF 由 Host 管理,VF 可直接分配给 VM;
- 每个 VF 拥有独立的寄存器、中断资源,VM 访问 VF 时直接与硬件交互,性能接近直通(如 NVIDIA GPU vGPU 的基础技术)。
- 设备扩展协议:进一步卸载 Host 开销:
- vDPA(vhost Data Path Acceleration):将 I/O 数据面(如数据包转发、磁盘读写)卸载到智能硬件(如 DPDK 网卡、存储加速卡),Host 仅负责控制面;
- VFIO(Virtual Function I/O):用户态设备直通框架,为 VM 提供安全的设备访问权限,同时支持中断重映射、DMA 隔离(GPU 直通的核心框架)。
QEMU/KVM: 虚拟化技术的生产级实现
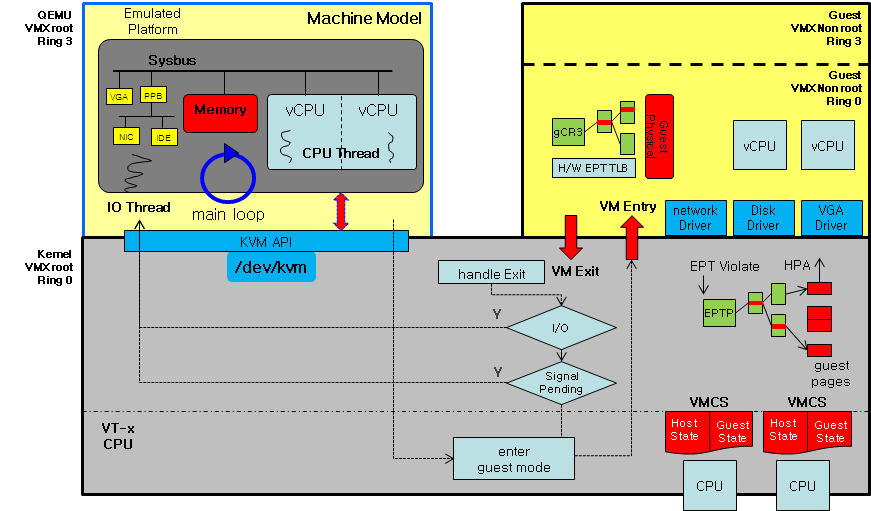

- KVM(Kernel-based Virtual Machine):
- 本质是 Linux 内核模块,提供 CPU(VT-x/AMD-V)与内存(EPT/NPT)的虚拟化能力;
- 支持 Root/Non-Root 双模式:Host 运行在 Root 模式,拥有硬件完全控制权;VM 运行在 Non-Root 模式,敏感操作触发 VM-Exit 并交给 KVM 处理。
- QEMU(Quick Emulator):
- 运行在用户空间,负责设备模拟(如网卡、磁盘、GPU 的软件模拟);
- 通过ioctl系统调用与 KVM 交互,请求创建 VM、vCPU,以及处理设备 I/O 的 VM-Exit 事件。
- VMCS(虚拟机控制结构):
- 上下文管理:保存虚拟机(Guest)和虚拟机监管器(Hypervisor)的 CPU 状态,包括寄存器、控制标志等。
- 行为控制:定义虚拟机运行时的权限、中断处理、I/O 访问等规则,决定何时触发 VM Exit(退出到 Hypervisor)。
- 状态切换:在 VM Entry(进入虚拟机)和 VM Exit 时,自动加载或保存上下文,实现虚拟机与 Hypervisor 的高效切换。
设备虚拟化的三种实现方式深度解析
纯软件的设备模拟
纯软件模拟(全虚拟化)通过虚拟机监控器(VMM/Hypervisor)完全以软件形式模拟硬件设备的行为,客户机操作系统无需感知虚拟化环境。以下是其核心实现原理与技术细节:
陷阱与模拟(Trap-and-Emulate)
- 特权指令截获:当客户机尝试执行特权指令(如 IN/OUT 访问 I/O 端口)时,触发 CPU 异常(如 #GP),VMM 捕获该异常并模拟设备响应。
- 内存映射拦截:客户机访问设备内存区域时,VMM 通过内存管理单元(MMU)拦截操作,转发到虚拟设备的处理逻辑。
设备状态虚拟化
- 寄存器模拟:为每个虚拟设备维护虚拟寄存器状态(如控制寄存器、状态寄存器),记录客户机的读写操作。
- 中断模拟:当虚拟设备需通知客户机时(如数据到达),VMM 注入虚拟中断(如通过 KVM_IRQ_LINE 通知 KVM)。
数据通路仿真
- I/O 请求处理:客户机的 I/O 请求(如磁盘读写)被 VMM 捕获,转发到宿主机文件或网络接口。
- DMA 模拟:模拟直接内存访问(DMA)操作,维护客户机物理地址到宿主机物理地址的映射。
代码示例与执行流程
虚拟机(VM)中运行的代码
1 | start: |
VM中没有操作系统,直接运行一段汇编代码。这段代码的功能是向端口0xf1发送字符串"Hello\n",然后通过hlt指令使处理器停机。
outb %al, $0xf1 指令将AL寄存器中的字节数据通过OUT指令发送到端口0xf1。每个mov指令将ASCII字符的十六进制值加载到AL寄存器。
发送的字节序列依次为:
1 | 0x48 → H |
组合后字符串为 “Hello\n”。
hlt指令停止处理器执行,进入休眠状态(通常用于程序终止)。
VMM实现代码
1 |
|
执行结果:
1 | $ gcc vmm.c -o vmm && ./vmm |
这段代码实现了一个极简的KVM虚拟机监控程序(VMM),用于加载并运行一个预编译的虚拟机镜像(vm.bin),并处理虚拟机的I/O操作和停机指令。其核心功能如下:
- KVM 环境初始化
- 打开
/dev/kvm设备,获取KVM API版本。 - 创建虚拟机(KVM_CREATE_VM)和虚拟 CPU(KVM_CREATE_VCPU)。
- 通过 mmap 分配 4KB 内存(0x1000),并将 vm.bin 文件内容加载到该内存区域。
- 设置虚拟机内存映射(KVM_SET_USER_MEMORY_REGION),将客户机物理地址 0 映射到宿主机用户空间内存。
- 虚拟机CPU配置
- 初始化虚拟CPU的段寄存器(KVM_GET_SREGS/KVM_SET_SREGS),将代码段(cs)基址设为 0。
- 设置指令指针寄存器 rip 为 0,使虚拟机从内存地址 0 开始执行代码。
- 虚拟机运行与事件处理
- 通过 KVM_RUN 启动虚拟机执行,进入事件循环。
- 处理退出原因:
- KVM_EXIT_HLT:当虚拟机执行 hlt 指令时,输出日志并正常退出。
- KVM_EXIT_IO:监控虚拟机对端口 0xf1 的输出操作(OUT 指令),打印发送的字符(如 Hello\n)。
- 其他退出原因:输出错误信息并终止。
VirtIO设备模拟
VirtIO(Virtual Input/Output)作为一种半虚拟化框架,是 Linux 基金会定义的半虚拟化标准,通过标准化的前后端通信协议和共享内存机制,显著提升了虚拟机与宿主机之间的I/O效率。通过 “Guest 前端驱动 + Host 后端设备 + 共享内存传输层” 的架构,在 “兼容性” 与 “性能” 之间取得最优平衡,是云环境中通用 I/O 的默认方案。
VirtIO 的高性能依赖于 “前后端分离” 的解耦设计,核心组件包括:
- 前端驱动(Front-End Driver):运行在 Guest OS 内核中,遵循 VirtIO 标准接口(如virtio-net网卡驱动、virtio-blk磁盘驱动),负责接收用户 I/O 请求并封装为标准化格式;
- 后端设备(Back-End Device):运行在 Host 侧(如 QEMU、vhost 内核模块),实现物理设备的功能映射(如将virtio-blk请求转发到 Host 磁盘文件、将virtio-net请求转发到物理网卡);
- 传输层(Transport Layer):基于共享内存的vring(环形缓冲区)机制,是前后端通信的核心 —— 前端将 I/O 请求放入vring的 “可用环(avail ring)”,后端处理后将结果写入 “已用环(used ring)”,实现异步无锁通信。
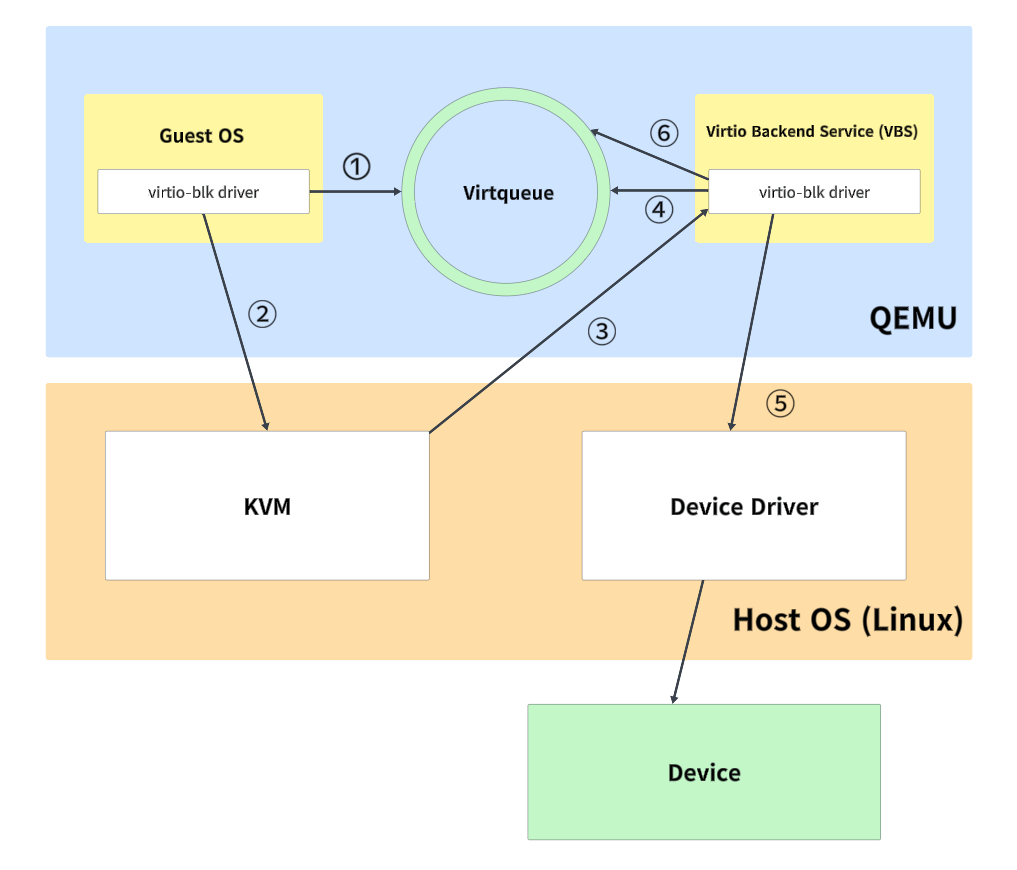
以 Guest 向虚拟磁盘写入数据为例,VirtIO 的完整 I/O 流程如下(核心是 “减少 VM-Exit 次数”):
前端驱动准备I/O请求:
前端在 Guest 共享内存中准备数据缓冲区(如要写入的磁盘块数据);
创建vring_desc(描述符),记录数据地址、长度、方向(写操作),并将多个描述符链接成 “描述符链”(支持分散 - 聚集 I/O);
驱动将这些描述符链接成一个描述符链,并将该链的头部索引放入Virtqueue的可用环(avail ring)中。
驱动更新可用环的idx索引(增加1),表明有一个新的请求可用。
前端驱动发送通知:
为了通知后端(Hypervisor)这个新请求的存在,前端驱动需要执行一个“门铃”操作。在MMIO传输方式下,这个“门铃”就是向一个特定的MMIO寄存器写入数据。
寄存器地址: 该寄存器的地址是virtio MMIO设备的基地址加上一个固定的偏移量。这个偏移量对应于QueueNotify寄存器。设备基地址通常由设备树(Device Tree)或ACPI表提供给Guest OS。
写入的数据: 前端驱动向QueueNotify寄存器写入一个16位(2字节)的无符号整数。数据的含义: 这个整数唯一代表的是要通知的Virtqueue的索引号(queue index)。例如:如果驱动刚刚向索引为0的Virtqueue(通常称为virtio0)添加了请求,它就向QueueNotify写入值0。如果设备有多个队列(例如多队列网卡),驱动会写入对应队列的索引(如1, 2等)。
触发VMExit和KVM处理:
对MMIO地址空间的QueueNotify寄存器的写操作,会被CPU识别为对设备寄存器的访问。
在虚拟化环境中(使用KVM),对设备MMIO区域的访问会触发VMExit,CPU控制权从Guest OS(用户模式)交还给KVM(宿主机内核)。
KVM的VMExit处理程序检查退出的原因(这里是MMIO写),并确定访问的是哪个virtio设备的哪个寄存器(这里是QueueNotify)。
KVM调用相应的virtio设备模拟后端(例如virtio-blk的后端驱动)。
后端处理:
virtio后端驱动接收到通知。
它从QueueNotify写入的值中提取出Virtqueue索引号(比如0)。
后端驱动根据这个索引号找到对应的Virtqueue。
后端驱动读取该Virtqueue的可用环(avail ring),获取新的可用描述符链的头部索引。
后端驱动遍历描述符链,从Guest RAM中读取请求的详细信息(操作类型、数据地址、数据长度等)。
后端驱动执行实际的I/O操作(例如,将数据写入宿主机上的磁盘文件或通过网络发送出去)。
I/O操作完成后,后端驱动将处理结果放入Virtqueue的已用环(used ring),并可能向Guest OS发送中断(另一个MMIO操作或MSI-X中断)通知前端驱动请求已完成。
Virtio之所以能够极大提升IO效率,是因为:
零拷贝 (Zero-Copy): 数据本身不需要在 Guest 用户态、Guest 内核态、Hypervisor 之间来回拷贝。后端直接从 Guest RAM 读取(发送操作)或写入(接收操作)。
减少 VMExit: 数据传递完全在共享内存中完成,只有通知和控制操作(如更新索引、发送通知)需要触发 VMExit。
批量处理与描述符链 (Batching & Descriptor Chaining):
描述符链: 一个 I/O 请求(如一个网络包或一个磁盘块请求)可以由多个描述符组成一个链。例如,一个网络包的元数据(头部)放在一个缓冲区,负载数据放在另一个缓冲区。前端驱动可以将这些分散的缓冲区链接成一个描述符链,一次性放入 Virtqueue。
后端批量处理: 后端收到通知后,可以一次性处理 Virtqueue 中所有新可用的描述符链(可能包含多个 I/O 请求)。这显著摊薄了单次通知和 VMExit 的开销。相比传统模拟每次小操作都可能触发 VMExit,Virtio 实现了高效的批量化。
高效的通知机制 (Efficient Notification):
- 前端 -> 后端 (kick): 如前所述,前端通过向一个简单的 MMIO 寄存器 (QueueNotify) 写入 Virtqueue 索引来通知后端。这是一个非常轻量级的写操作,只触发一次 VMExit,通知后端“请检查队列 X”
- 后端 -> 前端 (interrupt): Virtio 通常使用 MSI-X 中断。
特性协商 (Feature Negotiation):
- 启动时,前端和后端通过配置空间协商双方都支持的特性(如 VIRTIO_NET_F_MRG_RXBUF 用于合并接收缓冲区,VIRTIO_RING_F_EVENT_IDX 用于优化通知)。这允许驱动和设备只启用必要的、高效的特性,避免不必要的开销,并适应不同实现的优化点。
优化的后端实现 (Optimized Backend Implementation):
vhost: 为了极致优化(特别是网络),Linux 引入了 vhost 机制。
vhost (内核): 将 virtio 数据平面(队列处理、数据搬运)完全卸载到 Host 内核线程中运行。Guest 前端驱动通过 ioctl 将 Virtqueue 文件描述符传递给 vhost 内核线程。通知直接在内核上下文处理,完全绕过 QEMU 用户空间进程,消除了用户态-内核态切换和 QEMU 进程调度的开销。
vhost-user (用户态): 进一步将数据平面卸载到独立的用户态进程(如 DPDK/SPDK 应用)。通过 Unix Domain Socket 或共享内存通信,适用于高性能用户态网络/存储栈。
设备直通(PCI(e) Passthrough)
设备直通是将物理 PCIe 设备(如 GPU、NVMe SSD、高速网卡)直接分配给单个 VM 的技术,VM 通过 IOMMU 直接访问设备,完全绕过 Hypervisor,实现 “近乎物理机” 的性能,是 GPU 虚拟化、NFV 等极致性能场景的基础。
核心原理与架构
设备直通的实现依赖于两大硬件特性:
- IOMMU(I/O Memory Management Unit):
- 地址转换与隔离:IOMMU(Intel VT-d 或 AMD-Vi)为DMA设备提供物理地址到主机物理地址的转换能力,并强制实施访问权限检查。这确保了被直通给特定虚拟机的设备,其DMA操作只能访问该虚拟机被分配的内存区域,无法破坏其他虚拟机或宿主机的内存空间,解决了关键的安全问题。
- 中断重映射:IOMMU能够将设备产生的中断(如MSI/MSI-X)安全地重定向到正在运行的目标虚拟机对应的vCPU上,确保中断的正确传递和隔离。
- VFIO(Virtual Function I/O)框架:
- 这是一个现代、安全、基于用户态的设备直通框架,取代了老旧且不安全的
KVM-PCI-Assignment和xen-pciback方式。 - VFIO通过将设备驱动从宿主内核中解绑(unbind),并将其控制权移交(attach)给用户空间程序(如QEMU),实现了对直通设备的精细化和安全访问。
实现流程与关键步骤
将一台物理设备直通给虚拟机通常包含以下步骤:
- 启用IOMMU:在宿主机的BIOS/UEFI和内核启动参数中启用IOMMU支持。
- Intel: 在GRUB配置中添加
intel_iommu=on iommu=pt - AMD: 添加
amd_iommu=on iommu=pt
- 隔离设备:找到需要直通的设备的PCI地址(如
0000:01:00.0),并通过内核参数(如vfio-pci.ids=10de:1b80,10de:10f0)或手动操作,将其驱动程序绑定到vfio-pci驱动上。
1 | # 解绑当前驱动 |
- 配置虚拟机:在QEMU命令行中,使用
-device vfio-pci参数将设备添加到虚拟机。
1 | -device vfio-pci,host=01:00.0,multifunction=on |
- 虚拟机识别:启动虚拟机后,虚拟机操作系统将直接检测到物理设备,并需要安装相应的原生设备驱动程序(如NVIDIA GPU驱动)。
优势与挑战
| 优势 | 挑战与局限性 |
|---|---|
| 性能极致:近乎裸机的性能,延迟极低,吞吐量高。 | 资源独占:一个物理设备在同一时间只能被一个虚拟机独占,无法在多个VM间共享 |
| 功能完整:虚拟机可以使用设备的所有高级特性(如GPU的所有计算功能) | 兼容性问题:设备的ACPI、电源管理等功能可能在虚拟化环境中出现兼容性问题,导致虚拟机迁移(Migration)异常困难 |
| 降低CPU开销:数据路径完全绕过Hypervisor,大幅降低了宿主机的CPU占用率 | 硬件依赖性:要求主板、CPU、设备本身均支持IOMMU和中断重映射 |
| 简化驱动模型:虚拟机内使用标准驱动,无需安装特定的半虚拟化驱动 | 安全隔离依赖IOMMU:若IOMMU配置不当或存在漏洞,可能带来DMA攻击风险 |
在GPU虚拟化中的应用
PCIe Passthrough是实现GPU直通(GPU Passthrough) 的基础。它将整块物理GPU卡直接分配给一个虚拟机,为该VM提供最强的图形处理和通用计算(GPGPU)能力。这在AI训练、科学计算、高端图形设计和高性能游戏云等场景中是不可或缺的技术。
然而,其“一卡一VM”的模式也导致了资源利用率低下的问题。为了解决这一问题并实现单个物理GPU在多个虚拟机间的分时共享 和资源切分,行业在Passthrough的基础上发展出了更高级的虚拟化技术,如:
- SR-IOV(Single Root I/O Virtualization):允许物理设备被虚拟化为多个轻量级的虚拟功能(VF, Virtual Function),每个VF可以独立地直通给不同的虚拟机。这是NVIDIA vGPU和AMD MxGPU等技术的基础。
- Mediated Passthrough (mdev):一种软件辅助的直通方案,由一个宿主机的中介设备(Mediated Device) 模拟设备的控制层面,同时将数据层面的操作直接传递给物理设备。这为不支持SR-IOV的设备提供了共享虚拟化的可能。
结论:PCIe Passthrough是设备虚拟化性能的顶峰,它用资源独占换取了极致的性能和功能完整性,是GPU虚拟化技术栈中至关重要的一环,并为更复杂的共享虚拟化方案奠定了安全和性能隔离的基础。
参考文献
- Qemu官方文档: https://wiki.qemu.org/Documentation/Architecture
- 《QEMU/KVM源码解析与应用》 李强
- Linux Kernel VFIO文档:https://www.kernel.org/doc/html/latest/driver-api/vfio.html
- PCI-SIG SR-IOV标准:https://www.ibm.com/docs/en/power10?topic=networking-single-root-io-virtualization
 微信
微信- 支付宝